











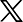


'독자 AI 파운데이션 프로젝트' 첫 성과
프롬 스크래치 방식으로 개발
딥시크·오픈AI 등 기능 상회
프롬 스크래치 방식으로 개발
딥시크·오픈AI 등 기능 상회
|

솔라 오픈은 업스테이지가 주관사로 참여 중인 과학기술정보통신부의 '독자 AI 파운데이션 모델 프로젝트'의 첫 번째 결과물이다. 데이터 구축부터 학습에 이르는 과정 전반을 독자적으로 수행하는 '프롬 스크래치' 방식으로 개발했다. 업스테이지는 해당 모델을 글로벌 오픈소스 플랫폼 '허깅페이스'에 공개하는 한편 개발 과정과 기술적 세부 내용을 담은 테크 리포트도 함께 발표했다.
솔라 오픈 100B는 1020억 개 매개변수를 갖춘 대형 모델로 글로벌 프런티어급 모델과 비교해도 경쟁력을 확보했다는 평가다. 업스테이지에 따르면 해당 모델은 중국의 대표 AI 모델인 딥시크 R1 대비 모델 규모는 약 15%에 불과하지만, 한국어·영어·일본어 등 주요 다국어 벤치마크에서 이를 상회하는 성능을 기록했다.
특히 한국어 능력은 압도적이다. 한국 문화 이해도(Hae-Rae v1.1), 한국어 지식(CLIcK) 등 주요 한국어 벤치마크 결과 딥시크 R1 대비 2배 이상의 성능 격차를 보였으며, 오픈AI의 유사 규모 모델인 'GPT-OSS-120B-Medium'과 비교해서도 100% 앞선 성능을 기록했다. 수학, 복합 지시 수행, 에이전트 등 고차원 영역에서도 글로벌 모델과 대등한 성과를 냈다는 설명이다.
이러한 고성능의 배경에는 약 20조 토큰 규모의 고품질 사전학습 데이터셋이 주효했다. 업스테이지는 대표적 '저자원 언어'인 한국어 데이터 부족을 극복하고자 다양한 합성 데이터와 금융·법률·의학 등 분야별 특화 데이터 등을 학습에 활용하고, 다양한 데이터 학습 및 필터링 방법론을 고도화했다. 향후 일부 데이터셋은 한국지능정보사회진흥원의 'AI 허브'를 통해 공개해 국내 AI 연구 생태계에 환원할 계획이다.
|
이러한 기술력은 국제적으로도 인정을 받았다. 미국 비영리 연구기관 에포크AI(Epoch AI)가 발표하고 스탠퍼드대 HAI(인간중심 AI 연구소) 보고서에 활용되는 '주목할 만한 AI 모델(Notable AI Models)' 리스트에 이름을 올리며, 한국이 글로벌 AI 3강으로 도약할 기술적 교두보를 마련했다는 평이다.
업스테이지는 노타, 래블업, 플리토, 한국과학기술원(KAIST), 서강대학교 등과 컨소시엄을 구성해 기술 협력을 이어가고 있다. 향후 금융·법률·의료·제조·공공·교육 등 산업별 파트너들과 협력해 AX(AI 전환) 기반 서비스를 확대하고, 미국·일본 법인을 거점으로 글로벌 시장 공략에도 속도를 낼 계획이다.
김성훈 업스테이지 대표는 "솔라 오픈은 업스테이지가 처음부터 독자적으로 학습해낸 모델로, 한국의 정서와 언어적 맥락을 깊이 이해하는 '가장 한국적이면서도 세계적인 AI'다"라며 "이번 솔라 오픈 공개가 한국형 프런티어 AI 시대를 여는 중요한 전환점이 될 것"이라고 밝혔다.






